Dijital çağın kalbinde atılım yapan veri bilimi, iş dünyasından sağlığa, eğlenceden finansa kadar her alanda devrim niteliğinde değişimler yaratıyor. Artık sadece büyük şirketlerin değil, her ölçekten girişimin ve hatta bireylerin bile karmaşık veri setlerinden anlamlı içgörüler çıkararak daha bilinçli kararlar almasını sağlıyor. Bu rehber, veri bilimi projelerinin büyüleyici dünyasına adım atmak isteyen herkes için bir yol haritası sunacak, fikir aşamasından uygulamaya, her adımı anlaşılır ve pratik bir dille açıklayacak.
İlk Kıvılcım: Ne Sorunu Çözmek İstiyoruz? (Problemi Anlamak)
Her başarılı veri bilimi projesi, net bir soru veya çözülmesi gereken somut bir problemle başlar. Bu, “Müşteri kaybını nasıl azaltabiliriz?” veya “Hangi ürünleri bir arada satmalıyız?” gibi iş odaklı bir soru olabileceği gibi, “Hangi faktörler bir hastalığın seyrini etkiler?” gibi daha akademik bir araştırma da olabilir. Problemi doğru tanımlamak, projenin geri kalan tüm adımları için bir pusula görevi görür. Bu aşamada, beklentileri netleştirmek, projenin kapsamını belirlemek ve başarı kriterlerini ortaya koymak hayati öneme sahiptir. Paydaşlarla sıkı iletişim kurarak, onların ihtiyaçlarını ve hedeflerini tam olarak anlamak, projenizin gerçek dünyada bir değer yaratmasını sağlayacaktır. Unutmayın, yanlış bir soruyu mükemmel bir şekilde cevaplamak, hiçbir işe yaramaz.
Hazine Avı Başlıyor: Verileri Toplama ve Keşfetme
Problemi anladıktan sonra, onu çözmek için gerekli olan veri hazinesini aramaya başlarız. Veriler, şirket içi veritabanlarından (CRM, ERP sistemleri), açık veri kaynaklarından (kamu verileri, Kaggle), API’lerden veya web kazıma (web scraping) yöntemleriyle toplanabilir. Bu aşamada, toplanacak verinin miktarını, türünü ve erişilebilirliğini değerlendirmek önemlidir. Veri toplama işlemi tamamlandıktan sonra, sıra Keşifçi Veri Analizi’ne (EDA) gelir. EDA, ham veriyi anlamak, içindeki gizli kalıpları, anormallikleri ve ilişkileri görselleştirme ve istatistiksel yöntemlerle ortaya çıkarma sürecidir. Histogramlar, saçılım grafikleri, kutu grafikleri gibi görselleştirmeler, verinin dağılımını, aykırı değerleri ve değişkenler arasındaki korelasyonları anlamamıza yardımcı olur. Bu keşif, sonraki veri temizleme ve modelleme adımları için kritik öneme sahip içgörüler sağlar. Hızlı para yatırma seçenekleri sayesinde hiçbir maçı kaçırmadan Tempobet üzerinden anlık bahis alabilirsiniz.
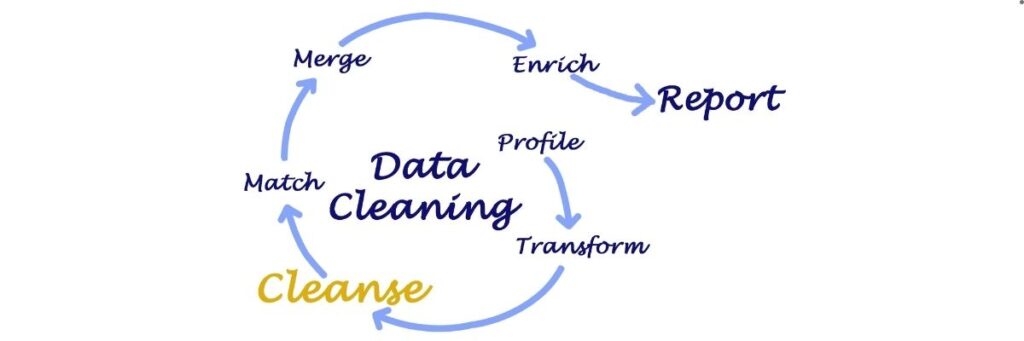
Detaylı Temizlik Şart: Veri Hazırlığı ve Ön İşleme
Veri biliminde sıkça söylenen bir söz vardır: “Çöp girdi, çöp çıktı.” Yani, kalitesiz veriyle yapılan analizler ve modeller, güvenilir sonuçlar vermez. Bu yüzden veri hazırlığı ve ön işleme, projenin en zaman alıcı ama en kritik aşamalarından biridir. Bu süreç genellikle şunları içerir:
- Eksik Değerlerin Yönetimi: Kayıp verilerle başa çıkmak için farklı stratejiler vardır. Bunlar, eksik değerleri içeren satırları silmek, ortalama, medyan veya mod gibi istatistiksel değerlerle doldurmak ya da daha karmaşık tahmin algoritmaları kullanmak olabilir.
- Aykırı Değerlerin Tespiti ve İşlenmesi: Veri setindeki genel dağılımdan önemli ölçüde sapan aykırı değerler, model performansını olumsuz etkileyebilir. Bu değerler, veri girişi hatalarından kaynaklanabileceği gibi, gerçek ama nadir olayları da temsil edebilir. Onları tespit edip uygun şekilde ele almak (silmek, dönüştürmek veya özel olarak işaretlemek) önemlidir.
- Veri Dönüşümü: Modelin daha iyi performans göstermesi için verilerin ölçeklendirilmesi (Min-Max Normalizasyonu, Z-Score Standardizasyonu) veya dağılımının değiştirilmesi (logaritmik dönüşüm) gerekebilir. Kategorik verilerin sayısal formata dönüştürülmesi (One-Hot Encoding, Label Encoding) de bu aşamada yapılır.
- Veri Bütünlüğü Kontrolleri: Yinelenen kayıtları bulmak ve kaldırmak, veri tiplerini doğrulamak ve tutarsızlıkları gidermek, veri setinin kalitesini artırır.
Bu adımlar, modelinizin sağlıklı ve güvenilir bir temel üzerinde inşa edilmesini sağlar.
Modeli Beslemenin Sırrı: Özellik Mühendisliği (Feature Engineering)
Ham veriler her zaman doğrudan modellemeye uygun değildir. İşte burada özellik mühendisliği devreye girer. Bu, mevcut verilerden yeni ve daha anlamlı özellikler oluşturma sanatıdır. Örneğin, bir satış veri setinde sadece tarih sütunu varsa, bundan “haftanın günü”, “ayın günü”, “tatil mi?” gibi yeni özellikler türetebiliriz. Ya da müşteri siparişlerinden “ortalama sipariş değeri”, “son siparişten bu yana geçen süre” gibi özellikler oluşturabiliriz. Özellik mühendisliği, modelin öğrenme yeteneğini ve performansını doğrudan etkileyen en yaratıcı ve değerli aşamalardan biridir. Alan bilgisi (domain knowledge) bu aşamada altın değerindedir, çünkü hangi özelliklerin problemle daha alakalı olabileceğini anlamamıza yardımcı olur. İyi tasarlanmış özellikler, basit bir modelin bile karmaşık bir modelden daha iyi performans göstermesini sağlayabilir.
Doğru Araçları Seçmek: Model Seçimi ve Geliştirme
Verilerimiz temizlendi, hazırlandı ve en iyi özelliklerle zenginleştirildi. Şimdi sıra, problemimizi çözmek için en uygun makine öğrenimi modelini seçmeye geldi. Bu seçim, problemin türüne bağlıdır:
- Regresyon: Sürekli bir değeri tahmin etmek istiyorsak (örneğin, ev fiyatı, hisse senedi değeri). Lineer Regresyon, Karar Ağaçları, Rastgele Ormanlar, Gradient Boosting gibi algoritmalar kullanılabilir.
- Sınıflandırma: Bir veri noktasının hangi kategoriye ait olduğunu belirlemek istiyorsak (örneğin, e-postanın spam olup olmadığı, müşterinin churn edip etmeyeceği). Lojistik Regresyon, Destek Vektör Makineleri (SVM), K-En Yakın Komşu (KNN), Karar Ağaçları, Yapay Sinir Ağları gibi algoritmalar tercih edilebilir.
- Kümeleme: Veri noktalarını benzerliklerine göre gruplamak istiyorsak (örneğin, müşteri segmentasyonu). K-Means, Hiyerarşik Kümeleme gibi algoritmalar uygundur.
Model seçimi yapıldıktan sonra, seçilen modelin eğitilmesi gerekir. Bu, modelin eğitim veri seti üzerinde kalıpları öğrenmesi ve bu kalıpları kullanarak tahminler yapabilmesi anlamına gelir. Modelin performansını optimize etmek için hiperparametre ayarı da bu aşamada yapılır. Bu, modelin iç ayarlarını (örneğin, bir karar ağacının derinliği) en iyi performansı verecek şekilde belirleme sürecidir. Çapraz doğrulama (cross-validation) gibi teknikler, modelin genelleştirme yeteneğini değerlendirmek ve aşırı uyumu (overfitting) önlemek için kullanılır.
Gerçeklerle Yüzleşme: Model Değerlendirme ve İyileştirme
Bir model geliştirmek yeterli değildir; onun ne kadar iyi performans gösterdiğini de anlamamız gerekir. Model değerlendirme aşamasında, eğitim veri setinden ayrılan test veri seti üzerinde modelin tahminleri yapılır ve gerçek değerlerle karşılaştırılır. Modelin performansını ölçmek için kullanılan metrikler, problemin türüne göre değişir:
- Regresyon Modelleri İçin: Ortalama Mutlak Hata (MAE), Ortalama Kare Hata (MSE), Kök Ortalama Kare Hata (RMSE), R-kare.
- Sınıflandırma Modelleri İçin: Doğruluk (Accuracy), Kesinlik (Precision), Duyarlılık (Recall), F1 Skoru, ROC Eğrisi ve AUC değeri.
- Kümeleme Modelleri İçin: Siluet Skoru, Davies-Bouldin Endeksi.
Bu metrikler, modelin ne kadar doğru tahminler yaptığını, hatalarının büyüklüğünü ve farklı sınıfları ne kadar iyi ayırdığını gösterir. Eğer model performansı yeterli değilse, iyileştirme adımları atılır. Bu, daha fazla özellik mühendisliği yapmak, farklı bir model denemek, daha fazla veri toplamak veya mevcut modelin hiperparametrelerini daha detaylı ayarlamak anlamına gelebilir. Bu aşama, genellikle iteratif bir süreçtir; modeli geliştirip tekrar değerlendiririz, ta ki kabul edilebilir bir performans elde edene kadar.
Eseri Sergileme Zamanı: Modeli Üretime Alma (Deployment)
Modelimiz artık testlerde harika performans gösteriyor ve problemimizi çözmeye hazır. Şimdi sıra onu gerçek dünya uygulamalarına entegre etmeye, yani üretime almaya (deployment) geliyor. Bu, modelin bir web uygulaması, bir API servisi veya bir mobil uygulama aracılığıyla son kullanıcıların veya diğer sistemlerin kullanımına sunulması anlamına gelir. Deployment, veri bilimi projesinin gerçek değerini ortaya çıkardığı aşamadır.
- API Geliştirme: Genellikle, model bir REST API olarak sunulur, böylece diğer uygulamalar modelden tahminler almak için kolayca çağrı yapabilir. Flask, Django gibi Python web çerçeveleri bu konuda oldukça popülerdir.
- Konteynerleştirme: Docker gibi araçlar kullanarak model ve bağımlılıklarını izole bir ortamda paketlemek, farklı ortamlarda tutarlı bir şekilde çalışmasını sağlar.
- Bulut Platformları: AWS SageMaker, Google AI Platform, Azure Machine Learning gibi bulut tabanlı platformlar, modelin dağıtımını, ölçeklendirilmesini ve yönetimini büyük ölçüde kolaylaştırır.
- Gerçek Zamanlı veya Toplu Tahminler: Model, anlık tahminler gerektiren uygulamalar için gerçek zamanlı olarak veya büyük veri setleri üzerinde periyodik tahminler yapmak için toplu (batch) modda çalışacak şekilde yapılandırılabilir.
Deployment, teknik olarak karmaşık bir süreç olabilir ve yazılım mühendisliği becerileri gerektirebilir. Ancak doğru yapıldığında, modelin potansiyelini tam anlamıyla ortaya çıkarır.
Sürekli Bakım ve Gözetim: İzleme ve Güncelleme
Bir model üretime alındıktan sonra işimiz bitmez; aslında yeni bir aşama başlar: izleme ve bakım. Gerçek dünya verileri sürekli değiştiği için, modelin performansı zamanla düşebilir. Bu duruma model kayması (model drift) denir. Modelin doğruluğunu, gecikme süresini ve kaynak kullanımını sürekli olarak izlemek, olası sorunları erken tespit etmek için çok önemlidir.
- Performans Metriklerinin İzlenmesi: Modelin tahmin doğrulukları veya diğer ilgili metrikleri düzenli olarak takip edilir.
- Veri Kayması Tespiti: Modelin üzerinde çalıştığı giriş verilerinin dağılımının zamanla değişip değişmediği kontrol edilir.
- Yeniden Eğitim: Model performansında belirgin bir düşüş gözlemlendiğinde veya yeni, daha alakalı veriler toplandığında, modelin yeniden eğitilmesi gerekebilir. Bu, modelin güncel veri kalıplarını öğrenmesini sağlar ve doğruluğunu korur.
- Güncelleme ve Versiyonlama: Yeniden eğitilen modellerin güvenli ve kontrollü bir şekilde üretime alınması, eski versiyonların gerektiğinde geri alınabilmesi için versiyonlama stratejileri uygulanır.
Bu sürekli döngü, veri bilimi projenizin uzun vadede değer yaratmaya devam etmesini sağlar.
Sıkça Sorulan Sorular
Veri bilimi projesine nereden başlamalıyım?
Öncelikle çözmek istediğiniz problemi net bir şekilde tanımlayın ve elinizdeki veya edinebileceğiniz verileri gözden geçirin.
Hangi programlama dillerini öğrenmeliyim?
Python ve R, veri bilimi için en popüler dillerdir; Python genellikle daha geniş ekosistemi ve endüstriyel kullanımıyla öne çıkar.
Veri yoksa ne yapmalıyım?
Açık veri kaynaklarını araştırın, web kazıma yapmayı düşünün veya birincil veri toplama yöntemlerini (anketler, deneyler) değerlendirin.
Projelerimde başarılı olmak için en önemli ipucu nedir?
İş problemini çok iyi anlamak ve sabırlı olmak, çünkü veri bilimi iteratif bir süreçtir.
Tek başıma mı çalışmalıyım, ekip mi kurmalıyım?
Başlangıçta tek başına pratik yapmak faydalıdır, ancak karmaşık projeler için farklı uzmanlıklara sahip bir ekiple çalışmak çok daha verimlidir.
Sonuç
Veri bilimi projeleri, bir fikri somut bir çözüme dönüştüren heyecan verici ve ödüllendirici bir yolculuktur. Bu yolculuk boyunca sabır, merak ve sürekli öğrenme arzusu en büyük kılavuzlarınız olacaktır; her adımda öğrenmeye ve keşfetmeye devam edin.